Abstract
Perceptual uncertainty is a central challenge for heterogeneous robot teams op- erating in unstructured outdoor environments, where no single viewpoint affords reliable scene understanding. Perceptual uncertainty, arising from sources such as occlusions, manifests differently across robot viewpoints depending on scene structure. Detecting and resolving sources of perceptual uncertainty requires both scene-based contextual reasoning and capability-aware robot allocation. While vision-language models provide strong semantic priors for both, they are com- putationally prohibitive for onboard inference and lack calibrated uncertainty quantification.
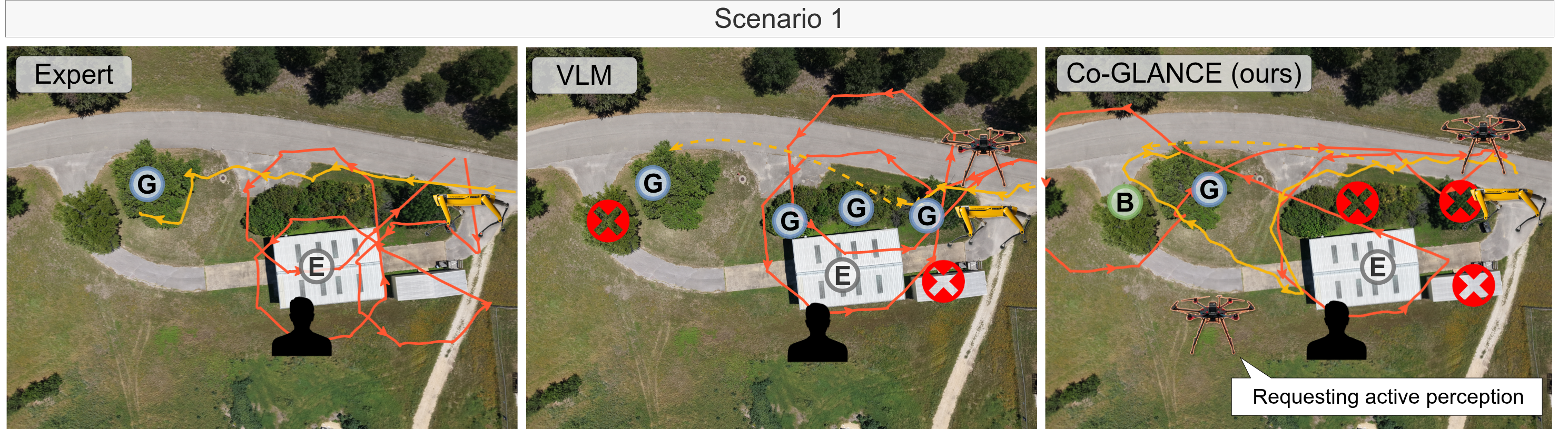
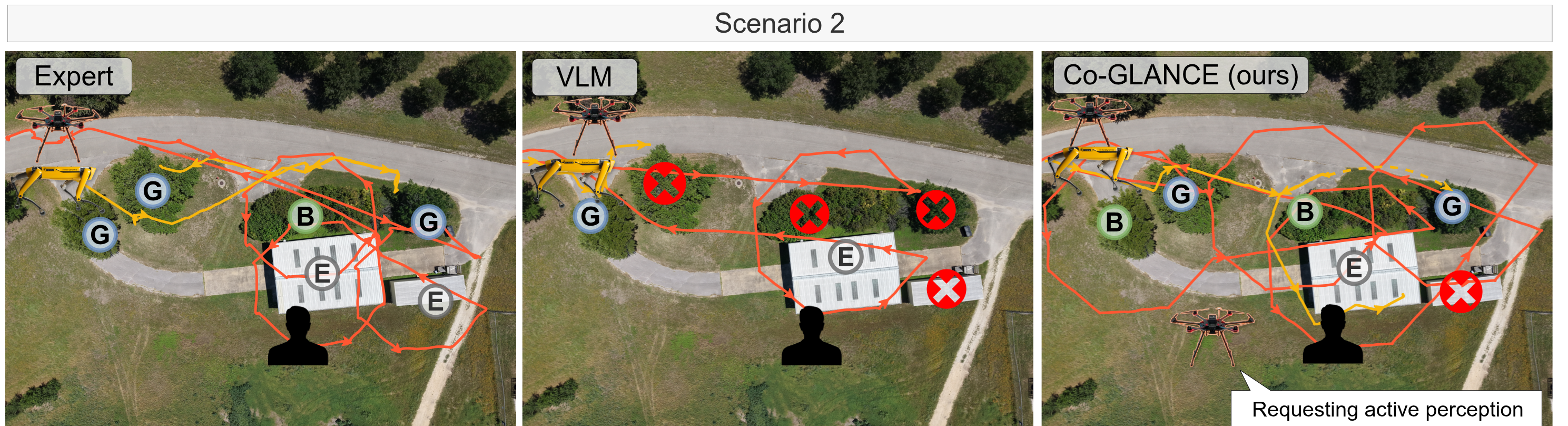
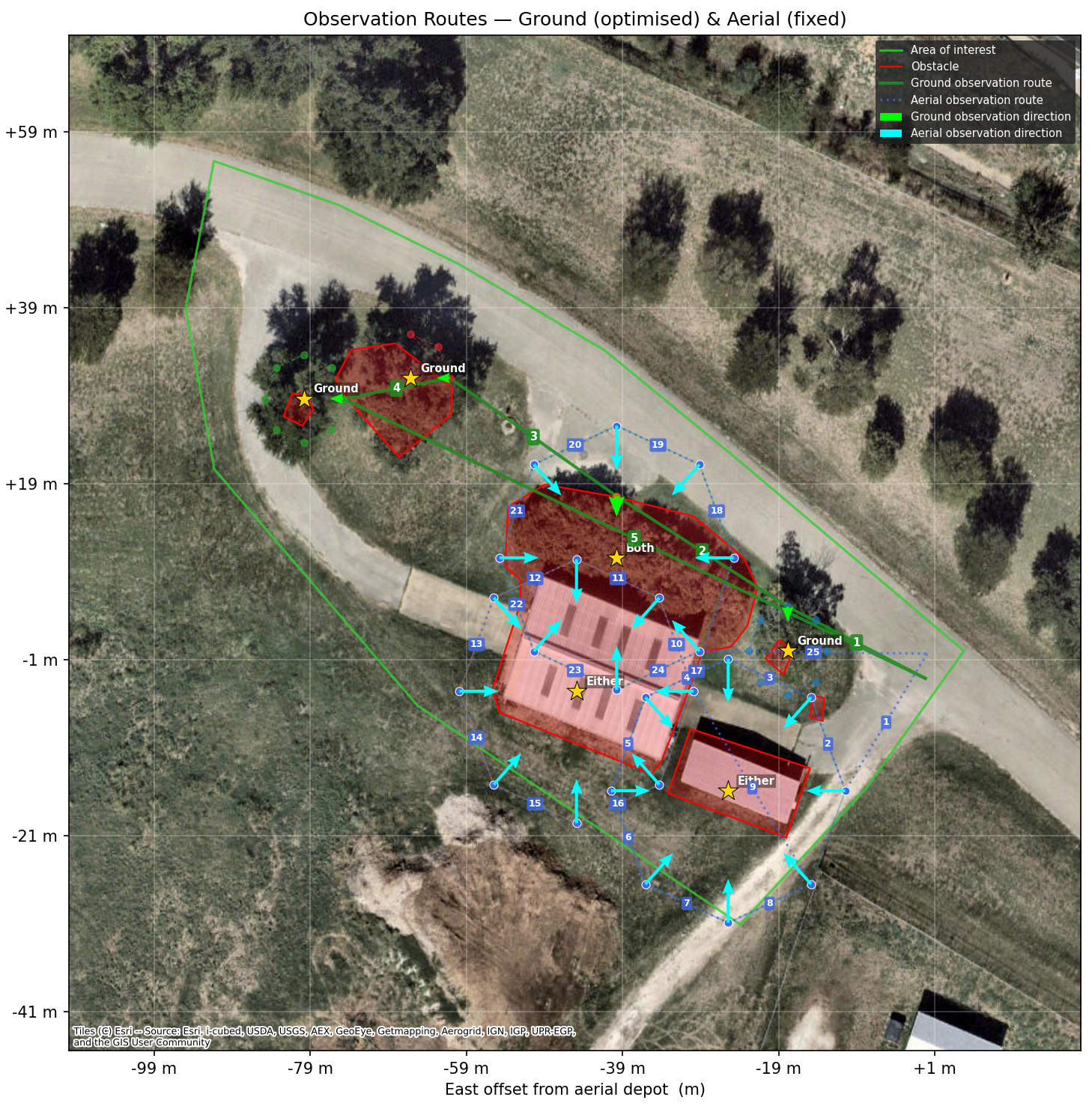
We introduce Co-GLANCE, a real-time onboard perception and decision-making system for uncertainty resolution in heterogeneous robot teams. Co-GLANCE distills the semantic reasoning capabilities of a vision-language model into an end-to-end model for occlusion segmentation and robot allocation, elim- inating the need for cloud-based inference. To quantify perceptual uncertainty, Co-GLANCE combines conformal prediction with selective abstention to provide statistically valid coverage guarantees for segmentation, robot allocation, and de- tection outputs. These calibrated uncertainty estimates directly trigger active per- ception, dispatching the most appropriate robot to acquire informative viewpoints and resolve uncertainty.
Across real-world scenarios, Co-GLANCE outperforms cloud-based vision-language model baselines in occlusion segmentation and robot allocation accuracy by 25% and 36%, respectively, while reducing per-frame in- ference latency 350×. We also release an air-ground dataset for future research. Code, videos, and dataset available at: co-glance.github.io.
An aerial robot and ground robot coordinate through communication for active perception.